Streaming data from Cloud Storage into BigQuery using Cloud Functions
Using Cloud Storage from Google Cloud Platform (GCP) helps you securely store your data and integrate storage into your apps. For real-time analysis of Cloud Storage objects, you can use GCP’s BigQuery. There are a bunch of options for streaming data from a Cloud Storage bucket into a BigQuery table. We’ve put together a new solution guide to help you stream data quickly into BigQuery from Cloud Storage. We’ll discuss in this post how to continually copy newly created objects in Cloud Storage to BigQuery using Cloud Functions.
Using Cloud Functions lets you automate the process of copying objects to BigQuery for quick analysis, allowing you near real-time access to data uploaded to Cloud Storage. This means you can get better information faster, and respond more quickly to events that are happening in your business.
Cloud Functions is GCP’s event-driven, serverless compute platform, which provides automatic scaling, high availability, and fault tolerance with no servers to provision, manage, update, or patch. Streaming data using Cloud Functions lets you connect and extend other GCP services, while paying only when your app is running.
Note that it’s also possible to stream data into BigQuery using Cloud Dataflow. Cloud Dataflow uses the Apache Beam framework, which provides windowing and session analysis primitives, as well as an ecosystem of source and sink connectors in Java, Python, and some other languages.
However, if you’re not fluent in the Apache Beam API and you’re trying to ingest files without considering windowing or complex transformations, such as streaming small files directly into tables, Cloud Functions is a simple and effective option.
You can also choose to use both Cloud Dataflow (Apache Beam) for complex ETL and large data sets, and Cloud Functions for small files and simpler transformations.
How this Cloud Functions solution worksThe following architecture diagram illustrates the components and flow of a streaming pipeline created with Cloud Functions. This pipeline assumes that you’re uploading JSON files into Cloud Storage, so you’ll have to make minor changes to support other file formats.
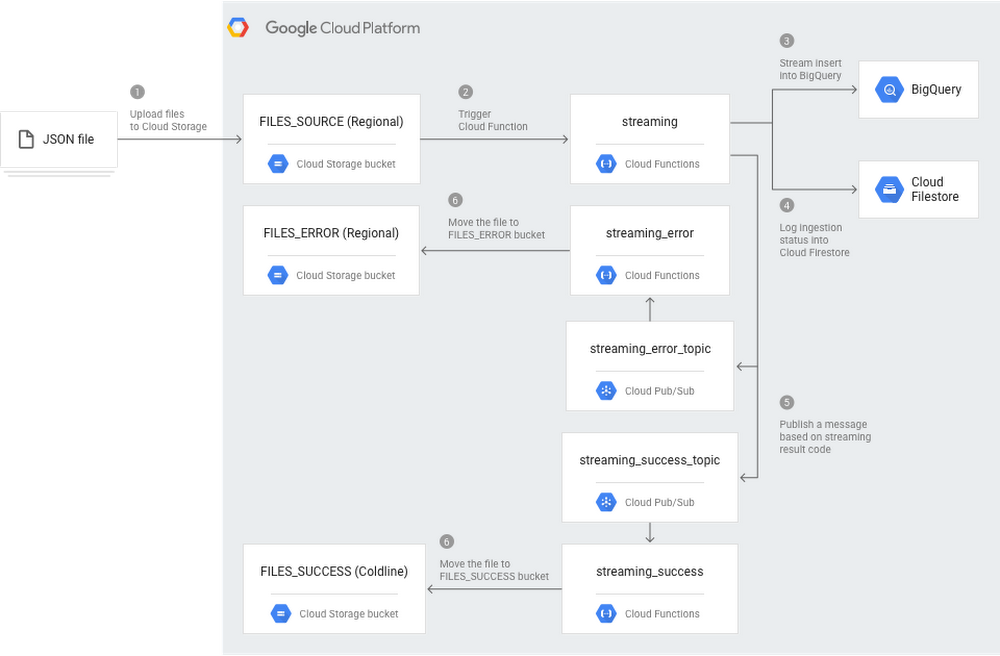
You can see in Step 1 that JSON files are uploaded to Cloud Storage. Every time a new file is added to the
FILES_SOURCE bucket, the streaming Cloud Function is triggered. This function parses the data, streams inserts into BigQuery (Step 3), logs the ingestion status into Cloud Firestore for deduping (Step 4), and publishes a message in one of the two Cloud Pub/Sub topics: streaming_success_topic, if everything went right; or streaming_error_topic, if any issue has happened (Step 5). At the end, either the streaming_error or the streaming_success Cloud Functions move the JSON file from the source bucket to either FILES_ERROR bucket or FILES_SUCCESS bucket (Step 6).
Using Cloud Functions means this architecture is not only simple but also flexible and powerful. Beyond lightweight scaling up and down to fit your file uploading capacity, Cloud Functions also allows you to implement custom functionalities, such as the use of Cloud Firestore.
Get started by visiting the solutions page tutorial, where you can get detailed information on how to implement this type of architecture. And try GCP to explore further.



Comments
Post a Comment