Skip the maintenance, speed up queries with BigQuery's clustering
BigQuery is Google Cloud’s serverless data warehouse, automating much of the toil and complexity associated with setting up and managing an enterprise-grade data warehouse. If there’s a maintenance task to be done, BigQuery’s philosophy is to take care of it for our users autonomously.
To get the most out of BigQuery, one of our key best practices is table partitioning and clustering. In this blog post, we’ll explain the internal workings of clustered tables in BigQuery. We’ll also cover automatic re-clustering, which fixes a classic data warehousing concern in a completely transparent way. It does this as a background process unique to BigQuery that continuously optimizes clustered tables for best performance.
You’ll find partitioning and clustering vastly improve the cost and performance profiles of your workloads. In addition, automatic re-clustering seamlessly provides a practical benefit: making your clustered tables resilient to real-world demands such as continuous inserts. One less thing to worry about!
How clustering works in BigQuery
Within a partitioned table, individual partitions behave as independent tables—one per partition. As such, the behavior of clustering for each partition of a partitioned table automatically extends to the clustering of non-partitioned tables.
Clustering is supported on primitive non-repeated top-level columns, such as INT64, BOOL, NUMERIC, STRING, DATE, GEOGRAPHY, and TIMESTAMP.
In general, there are two typical usage patterns for clustering within a data warehouse:
- Clustering on columns that have a very high number of distinct values, like
userIdortransactionId. - Clustering on multiple columns that are frequently used together. When clustering by multiple columns, the order of columns you specify is important. The order of the specified columns determines the sort order of the data. You can filter by any prefix of the clustering columns and get the benefits of clustering, like
regionId,shopIdandproductIdtogether; orregionIdandshopId; or justregionId.
Data in a BigQuery table is stored in Capacitor format blocks. This means that table clustering defines a “weak” sort order on these blocks. In other words, BigQuery attempts to distribute the data such that the blocks store non-overlapping ranges of values for the clustering keys. BigQuery automatically determines the boundaries of these new blocks within each partition as it is written to a table.
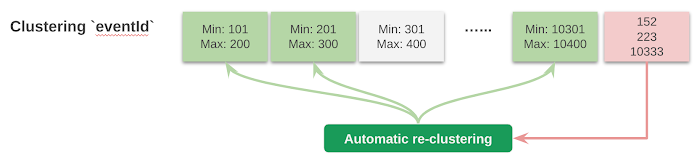
You can see below the layout of data in a table partitioned on the
eventDate date column and clustered on the eventId clustering column:
In this query, BigQuery first applies the filter on the partitioning column to limit the blocks to only those in partition for “2019-08-02.” Additionally, since the table is clustered on
eventID, blocks are organized so that there are non-overlapping ranges of values for eventID column. Among other things, BigQuery’s scalable metadata management system stores the range information of columns within each block. It uses this information to further limit the scan to blocks that have eventId between 201 and 300, as well as between 10301 and 10400.
Clustering improves performance of aggregation queries
Since clustering implies sort order, rows with the same value for the clustering columns are stored in the same or nearby blocks. This allows BigQuery to optimize aggregation queries that group by the clustering columns. In order to compute aggregates, BigQuery first computes partial aggregates from each block. It then shuffles and merges these partial aggregates to compute the final aggregate. Since rows with same value for clustering columns are generally together, partial aggregations produced are significantly smaller in size, thus reducing the amount of intermediate data that needs to be shuffled. This improves aggregation query performance.
Maintaining table clustering
Data is typically written to a BigQuery table on a continuous basis using load, query, copy jobs or through the streaming API. As more data comes in, the newly inserted data may be written to blocks that have column value ranges that overlap with those of the currently active blocks in the table. To maintain the performance characteristics of a clustered table, BigQuery performs automatic re-clustering in the background to restore the sort property of the table. Remember, in a partitioned table, clustering is maintained for data within the scope of each partition.
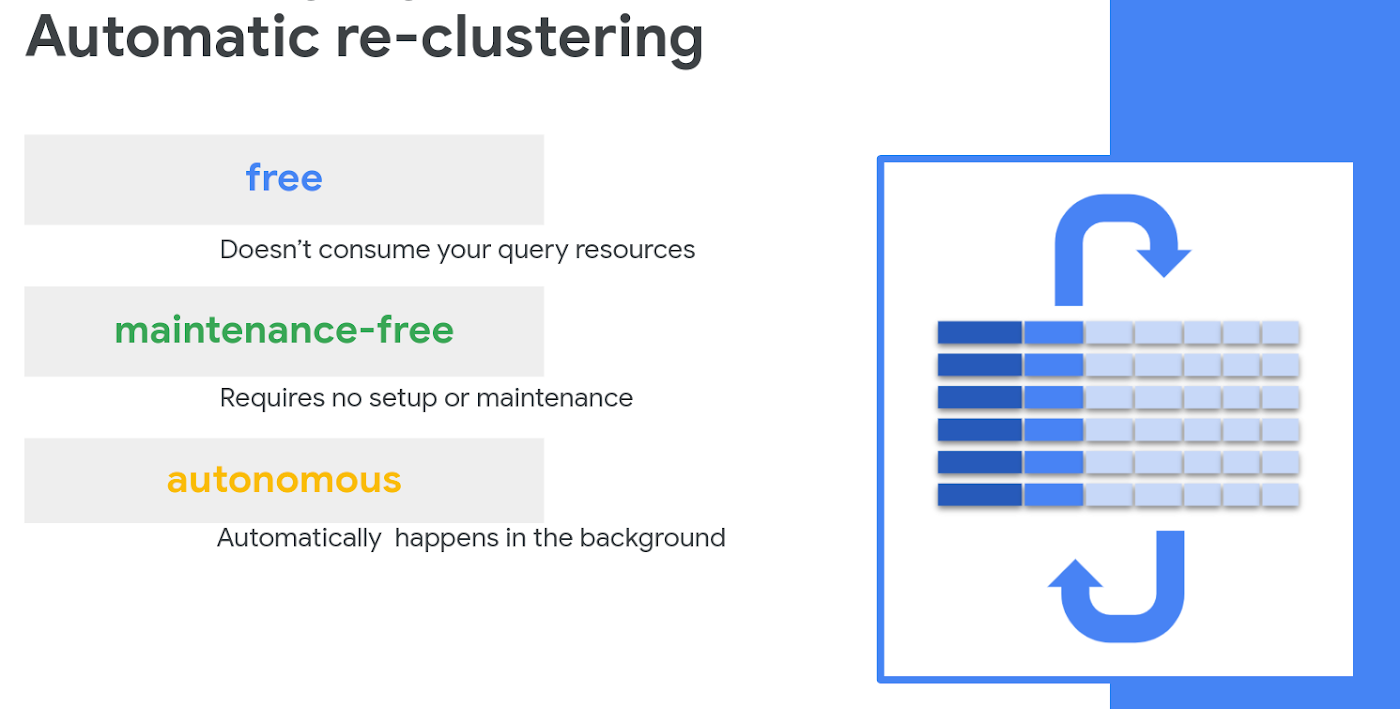
Traditionally, similar processes in data warehouses, such as VACUUM or automatic clustering, require some level of setup and administration. They also require the user to bear the cost of the process, since the processes use cluster time otherwise dedicated to valuable analytics. BigQuery’s automatic re-clustering is unique in two ways:
- This background operation does not use any of your resources, and is thus provided free to users.
- The system performs automatic re-clustering autonomously and transparently, with no action required from you.
How automatic re-clustering works
Automatic re-clustering works in a manner similar to an LSM tree. In steady state, most of the data in a partition is in fully sorted blocks, referred to as the baseline. As new data is inserted into a partition, BigQuery may either perform a local sort for the new data or defer such sorting until there is sufficient data to require a write. Once there is sufficient amount of data, the system generates locally sorted blocks, called deltas. After the deltas have accumulated enough data, comparable in size to the size of the current baseline, BigQuery merges the baseline and deltas to generate a new baseline. While regenerating baselines is I/O- and CPU-intensive, you won’t notice it one bit.
Learn more about using BigQuery
In addition to making auto re-clustering completely free and autonomous for our users, you don’t pay for ingest into BigQuery, and query capacity is not consumed one bit. We hear from customers that these two workloads combined can consume up to 30% of their processing resources that could otherwise be dedicated to business-critical analytics and data processing. BigQuery’s approach means that these efficiencies directly translate to a more resilient data warehouse, providing faster queries and more savings.
For more practical examples of the cost and performance impact of clustering, head over to Felipe Hoffa’s blog post on clustering. As always, you can try BigQuery with our free perpetual tier of 1TB of data processed and 10GB of data stored per month.



Comments
Post a Comment