New Cloud Security Podcast by Google is here

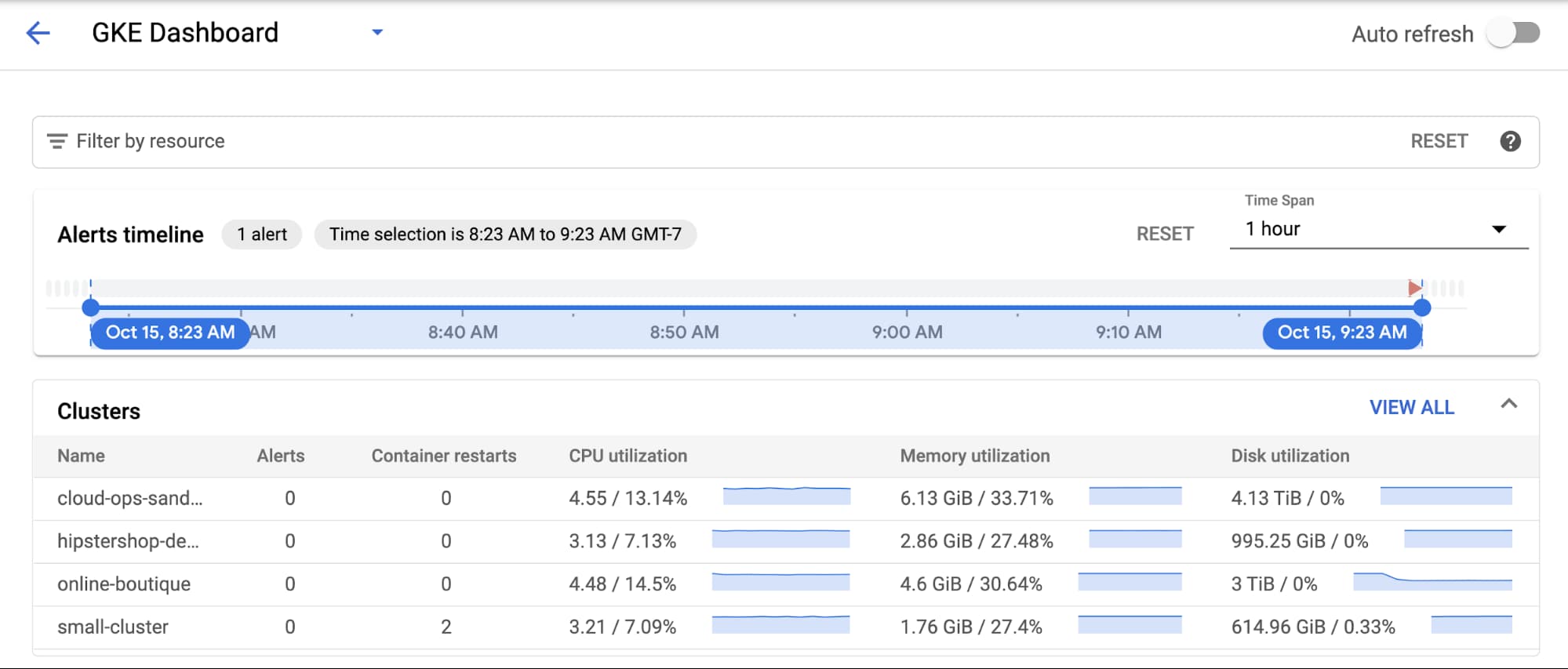
Applications fail. Containers crash. It’s a fact of life that SRE and DevOps teams know all too well. To help navigate life’s hiccups, we’ve previously shared how to debug applications running on Google Kubernetes Engine (GKE). We’ve also updated the GKE dashboard with new easier-to-use troubleshooting flows. Today, we go one step further and show you how you can use these flows to quickly find and resolve issues in your applications and infrastructure.
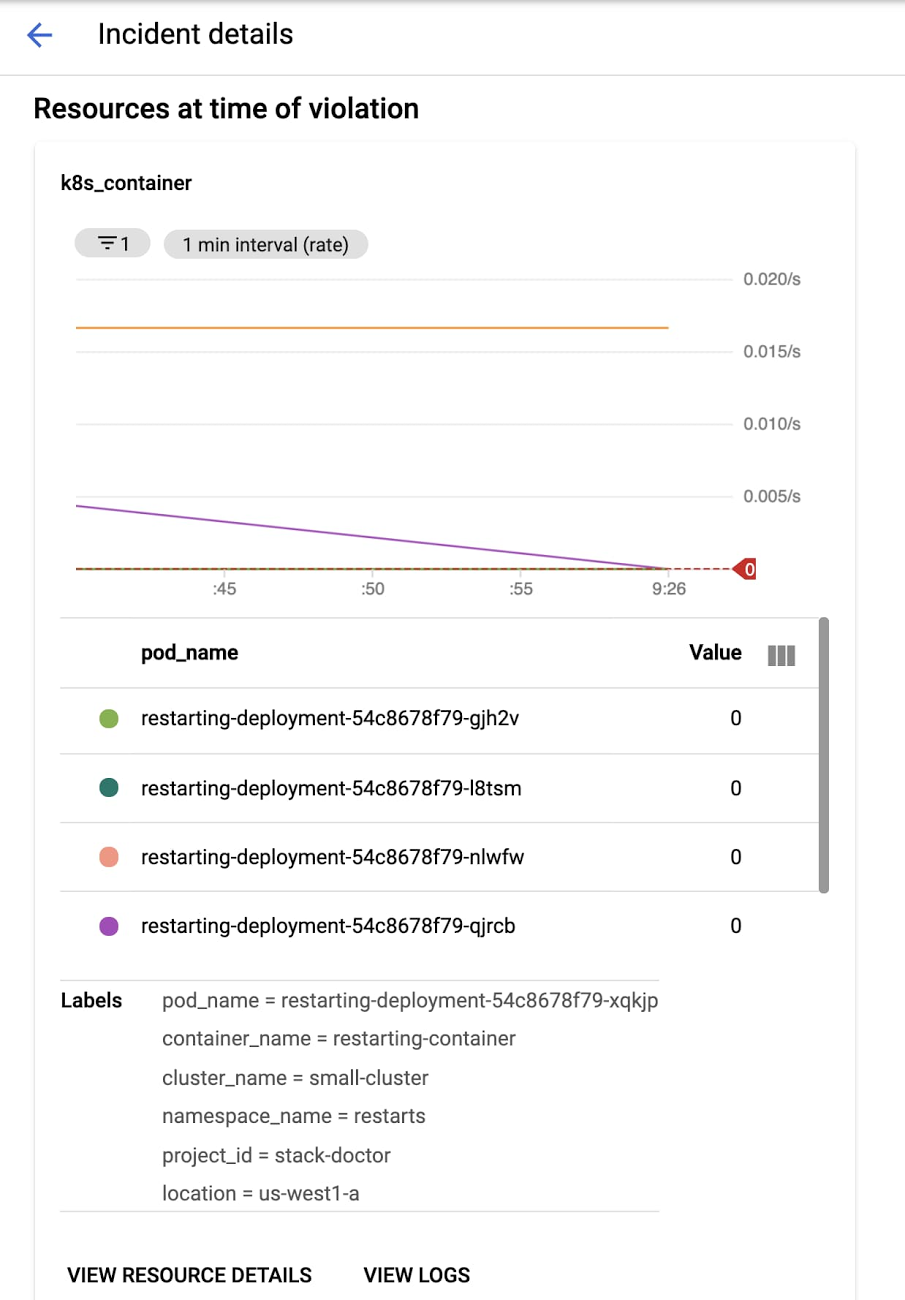
In this blog, we'll walk through deploying a sample app to your cluster and configuring an alerting policy that will notify you if there are any container restarts observed. From there, we'll trigger the alert and explore how the new GKE dashboard makes it easy to identify the issue and determine exactly what's going on with your workload or infrastructure that may be causing it.
Setting up
Deploy the app
This example uses a demo app that exposes two endpoints: an endpoint at /, which is just a "hello world", and a /crashme endpoint, which uses Go's os.Exit(1) to terminate the process. To deploy the app in your own cluster, create a container image using Cloud Build and deploy it to GKE. Then, expose the service with a load balancer.
Once the service is deployed, check the running pods:
Notice that RESTARTS is initially at zero for each pod. Use a browser or a command line tool like curl to access the /crashme endpoint. At this point, you should see a restart:✗ kubectl get podsNAME READY STATUS RESTARTS AGErestarting-deployment-54c8678f79-gjh2v 1/1 Running 0 6m38srestarting-deployment-54c8678f79-l8tsm 1/1 Running 0 6m38srestarting-deployment-54c8678f79-qjrcb 1/1 Running 0
✗ kubectl get podsNAME READY STATUS RESTARTS AGErestarting-deployment-54c8678f79-gjh2v 1/1 Running 1 9m28srestarting-deployment-54c8678f79-l8tsm 1/1 Running 0 9m28srestarting-deployment-54c8678f79-qjrcb 1/1 Running 0 9m28s
while true;docurl http://$IP_ADDRESS:8080/crashme;sleep 45;done
where $IP_ADDRESS is the IP address of the load balancer you've already created.
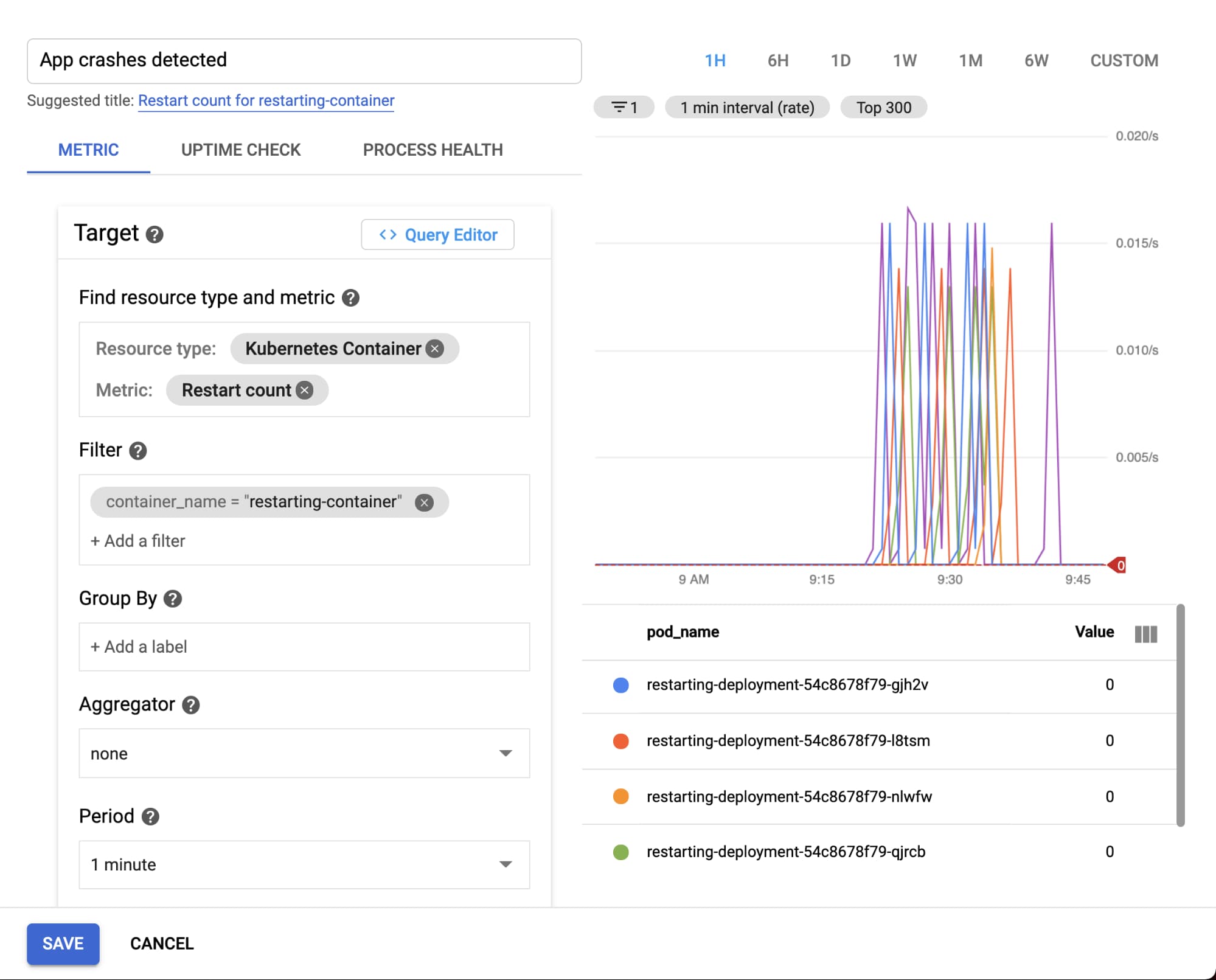
Why do container restarts matter? Well, restarts, to a certain degree, are an expected part of a container’s typical lifecycle in Kubernetes. Too many container restarts, however, could affect the availability of your service, especially when expanded over a larger number of replicas for a given Pod. Not only do excessive restarts degrade the service in question, but they also risks affecting other services downstream that use it as a dependency.
In real life,the culprit for a large number of restarts could be a poorly designed liveness probe, issues like deadlocks in the application itself, or misconfigured memory requests that result in OOMkilled errors. So, it is important for you to proactively alert on container restarts to preempt potential degradation that can cascade across multiple services.
Configure the alert
Now, you're ready to configure the alert that will notify you when restarts are detected. Here's how to set up your alerting policy:





Comments
Post a Comment